
Data Engineering within the hospitality industry - Personal Project
August 2024
Ever since I was young, I have always grown up within the restaurant industry. My parents always owned a restaurant or were working within the hospitality services. Since I have become older and gained theoretical and work experiences within the world of data, I became more aware of how much data can be extracted and used to increase decision-making of restaurant owners. My parents used their gut-feeling and/or a short horizon (approximately a week) to “forecast” how busy the restaurant may be. So it was not based on facts or figures.
This leads to the personal project of my brother and me to initiate a platform for extracting and visualising data. He started the project by creating a front-end with Flask, JavaScript, Python and Google Sheets (not a massive fan of the last one, but he needed to start in some form or way). The first setup contained the turnover each day and some visualisations to present it:
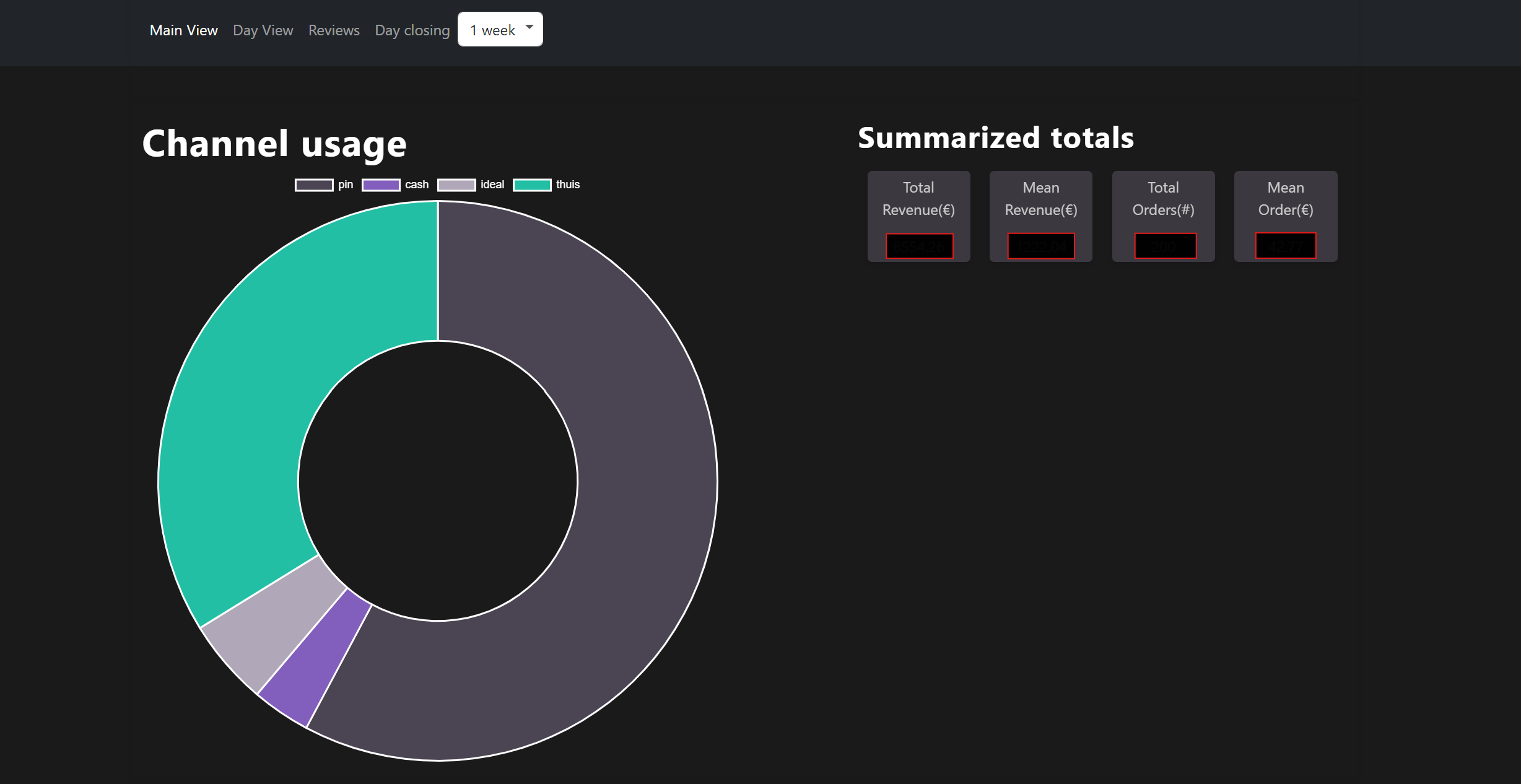
After he managed to set up the first version, he was able to run the application locally in Flask. It was time for me to step in and create new data sources, create automated data pipelines and set up a platform for deployment.
Note: This page will get updated along the way due to new insights and updates towards the application.
Design
The following tooling has been used for designing, managing and deploying the app and ETL services:
- Google Cloud Platform
- Platform
- API & Services: for enabling the APIs needed to operate within the GCP platform.
- App Engine: the service for publishing the app.
- Billing: for monitoring the billing parts concerning the used cloud services.
- Cloud Storage: storage for every used cloud service.
- Cloud Run: service for operating the setup of Cloud Functions.
- IAM & Admin: for providing and revoking access for different users and GCP services.
- Data Engineering
- BigQuery: used as data warehouse for analytics and powering the dashboard with data.
- Cloud Run Functions: functions which are created in Python for the different ETL stages with all targeted to the BigQuery data warehouse.
- Cloud Scheduler: the scheduled triggers for single Cloud Functions.
- Platform
- Python
- SQL (BigQuery)
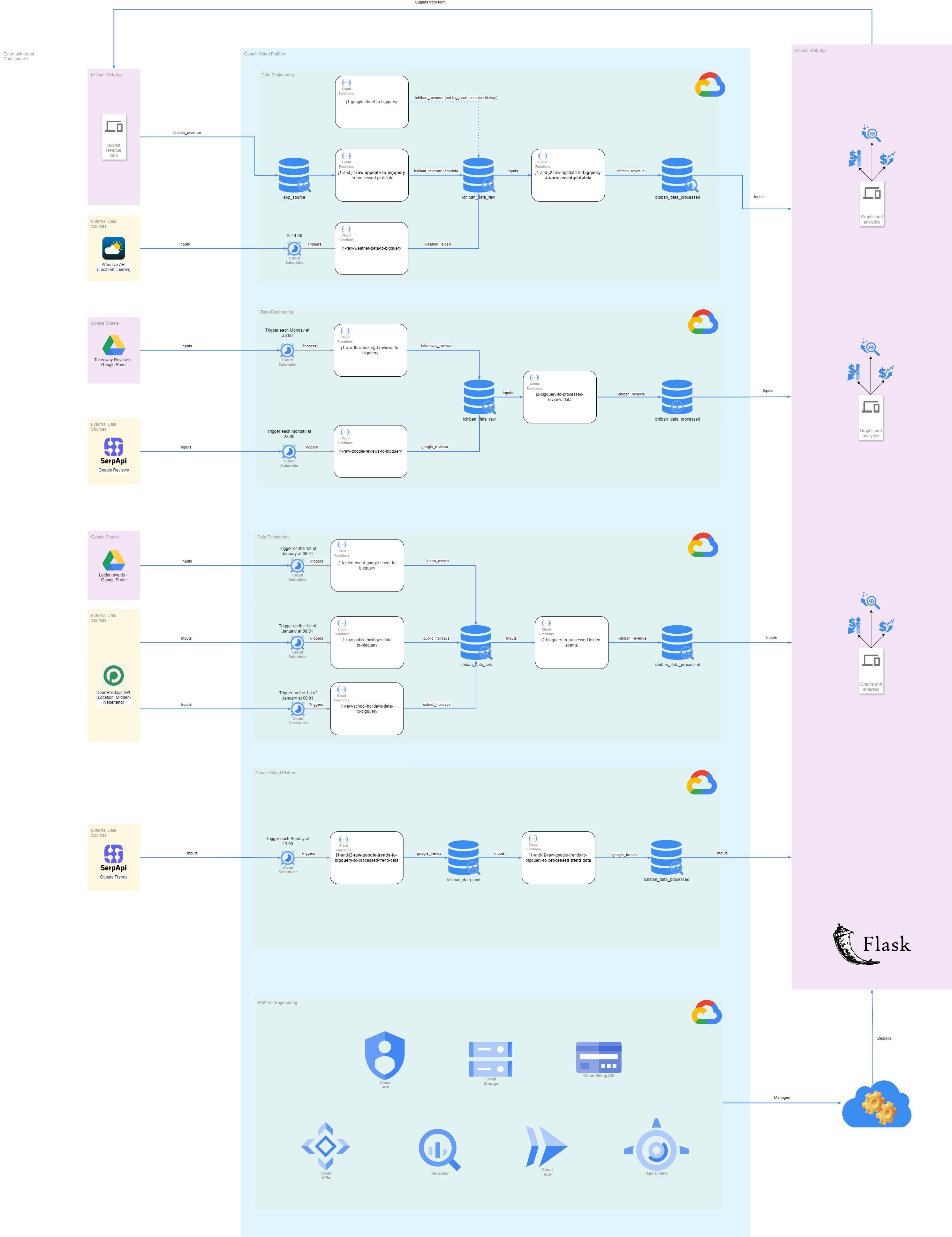
This can be translated in the following landscape architecture:
And for project management and documentation, the following tools were used:
- Notion
- draw.io
Data Models
The tables that we have taken into account for this entire platform is the following:
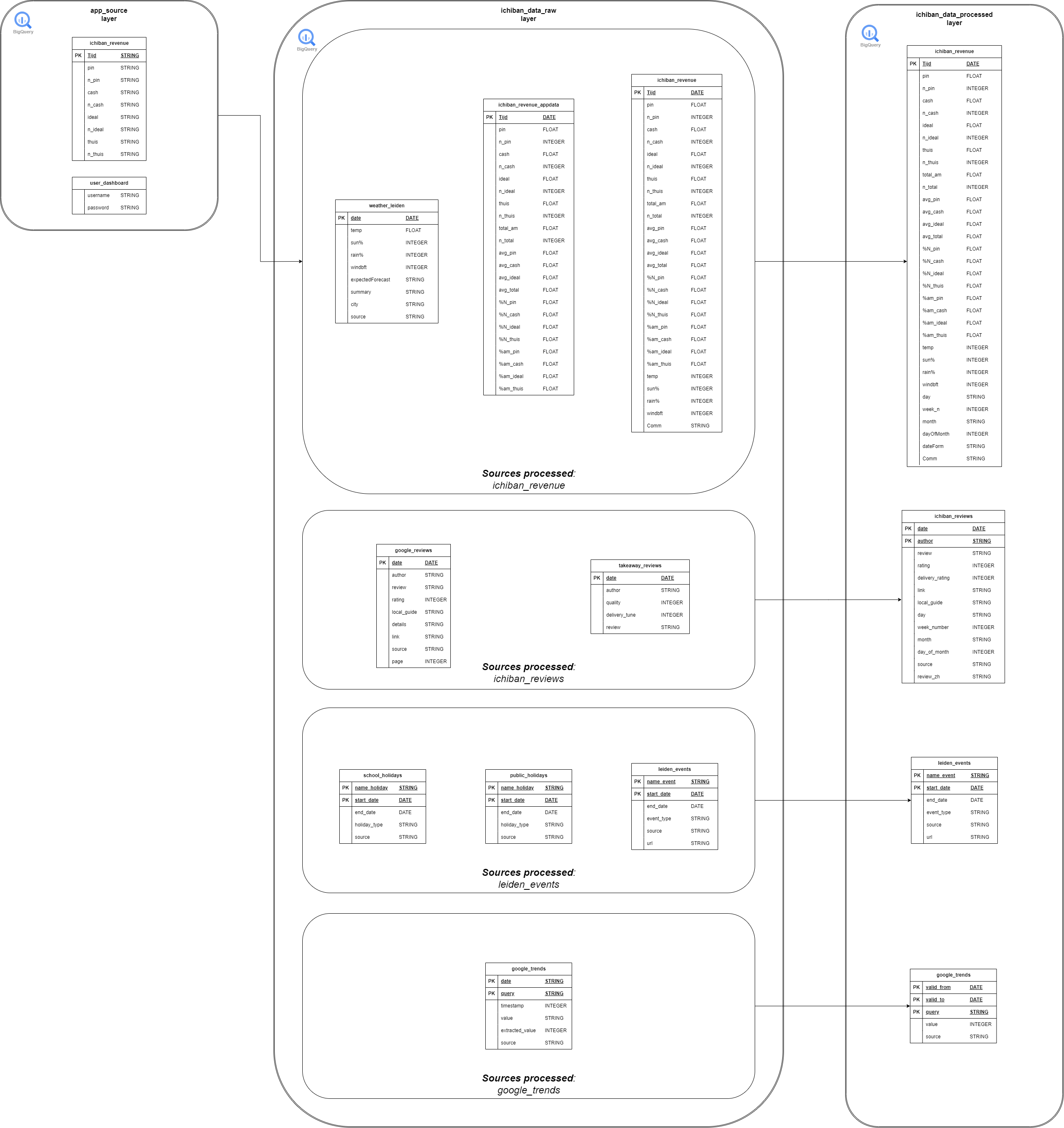
Code
Most code for operating the Google Cloud services can be found here.
Lessons Learned
Since we have started migrating from a Google Sheet to the services provided by the Google Cloud Platform, the following lessons learned were drawn from experiments and proof-of-concepts (POC) within our environments:
- In June 2024:
- We have done an experiment to increase the computing from
0instances to1instance being on all the time. This resulted in an increase of €20,- in our billing for that particular month. Since our app is still in an experimental phase, we have decided to set the application back again to a cold warmup setup. This lead to a cost of approximately €10,- per month, mostly resulting from the App Engine service. - A POC was done with Google Cloud Composer, which was replacing the dependencies via separate Cloud Functions. Airflow DAGs were created to run it. Even though the functionalities were working well, the costs skyrocketed due to Cloud Composer being active all the time. This resulted in an increase of costs of €15,- for approximately 4 days. This resulted in the decision to just chain all the Cloud Functions together. Whenever the final “Processed” Cloud Function job was dependent on two Cloud Functions jobs coming from the “Raw” layer, then the final job was scheduled 30 minutes later. This to prevent any delays coming from the previous jobs. It is working fine till date, and the costs decreased again to only the App Engine bills.
- We have done an experiment to increase the computing from
- In August 2024:
- A small configuration experiment was done to decrease the default value of
0.6oftarget_cpu_utilizationandtarget_throughput_utilizationto0.5. This resulted in a quicker and better performing web app, whereas the costs did not exceed the €10,- for August.
- A small configuration experiment was done to decrease the default value of
- In September 2024:
- Noticed that we have reached the limit of
10000 fileswhen deploying the new application. This was caused by the fact that the.venvfiles were added with the deployment. This leads the app to be of the size of 1 GB. When adding it to the.cloudignorefile, the app decreased in size from 1 GB to 400 MB (and also being able to be deployed of course).
- Noticed that we have reached the limit of